Acquisition Battle #1 : SKAN vs Modèle Probabiliste

L’attribution mobile a profondément évolué ces dernières années, en grande partie en réponse à l’App Tracking Transparency d’Apple, qui a bouleversé les pratiques en matière de collecte et d’analyse des données. Dans ce nouveau cadre, deux approches principales émergent sur iOS pour répondre aux défis des annonceurs : SKAN vs modèle probabiliste.
D’un côté, SKAN, conçu par Apple, fait de la confidentialité des utilisateurs sa priorité avec un cadre rigide mais universel pour les campagnes iOS. De l’autre, le modèle probabiliste s’est démocratisé en offrant une alternative visant à compenser certaines limites imposées par l’ATT.
Avant de commencer
Pour mieux comprendre les bases de ces deux approches, nous vous invitons à explorer ces articles détaillés :
Alors, SKAN vs modèle probabiliste. quelles sont les forces et les limites de chaque modèle ? Place au duel.
Points clés
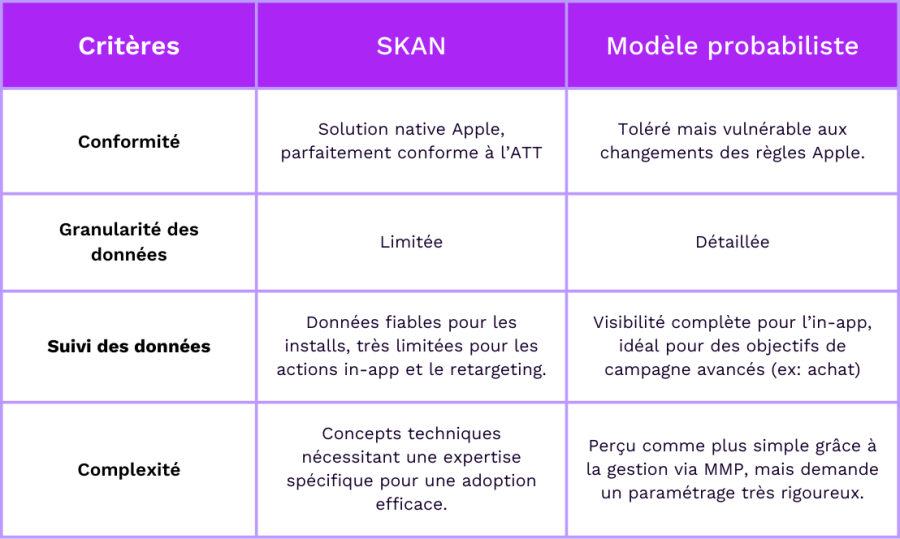
- Précision des données : SKAN = données limitées, postbacks différés et faible granularité. Probabiliste = données instantanées, flexibles, mais dépend fortement de la qualité des signaux et du paramétrage.
- Conformité : SKAN = 100 % conforme aux règles Apple. Probabiliste = toléré mais plus vulnérable aux évolutions réglementaires.
- Lisibilité : SKAN fiable pour mesurer les installs, mais limité pour le post-install. Probabiliste = visibilité complète sur le funnel, y compris achats et abonnements.
- Complexité : SKAN demande une vraie expertise technique (postbacks, valeurs, fenêtres). Probabiliste = plus simple via les MMP, mais sensible aux erreurs de configuration.

Round 1 : La précision des données
SKAN
SKAN, avec ses seuils de confidentialité, la limitation du nombre de Campaign IDs et les délais de réception des postbacks (24 à 48 heures), complique l’analyse granulaire des performances. Bien que les tiers d’anonymat introduits avec SKAN 4.0 apportent des améliorations, ces contraintes restent néanmoins un frein pour une lecture détaillée des événements post-install, rendant les ajustements rapides plus difficiles en acquisition.
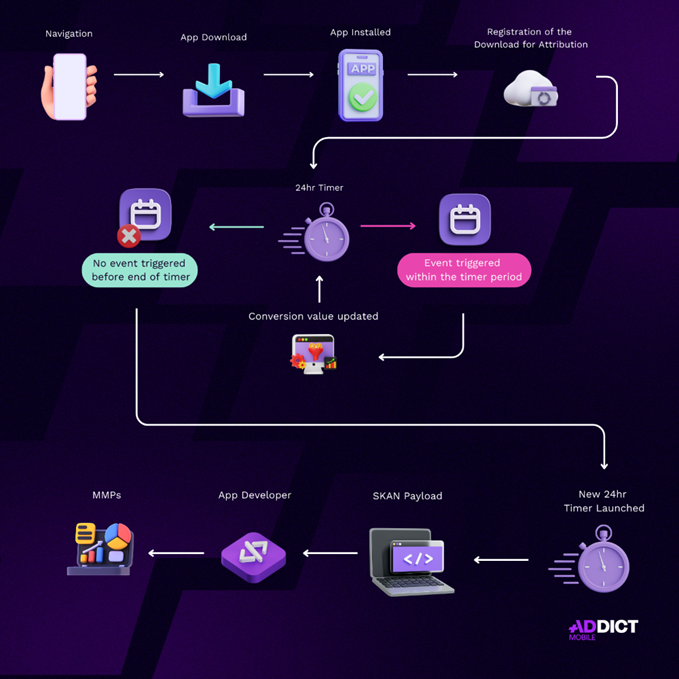
Modèle Probabiliste
De son côté, le modèle probabiliste excelle en termes de granularité et de rapidité. Pas de délais dans la transmission des données, une flexibilité dans les fenêtres d’attribution via les outils MMP : les annonceurs ont une vue précise de la performance à chaque étape. Mais attention : sa précision repose sur la qualité des données initiales et des algorithmes. Une configuration mal calibrée peut entraîner des biais ou une sur ou sous-attribution, ce qui fausse la mesure des performances.
Round 2 : Conformité avec les réglementations
SKAN
SKAN est la solution développée par Apple en réponse aux exigences introduites par l’ATT. En éliminant l’utilisation des identifiants personnels, SKAN s’inscrit parfaitement dans ce cadre de confidentialité stricte, offrant aux annonceurs une conformité totale avec les règles d’iOS et une tranquillité d’esprit face aux évolutions des politiques de l’écosystème Apple.
Modèle Probabiliste
Le modèle probabiliste, bien qu’actuellement toléré, est plus vulnérable aux changements de politiques. Certaines méthodes reposent sur des identifiants publicitaires qui pourraient être affectés par un durcissement des règles d’Apple. Pour rester conformes, les annonceurs doivent donc rester vigilants et prêts à adapter leurs pratiques, ce qui peut prendre du temps et impacter les performances tant que les ajustements nécessaires ne sont pas pleinement opérationnels.
Round 3 : Lisibilité et suivi des données
SKAN
SKAN est une solution fiable pour mesurer les volumes d’installations, même si les données peuvent parfois être légèrement sous-estimées. Mais son vrai point faible reste la visibilité in-app, fortement limitée par les thresholds imposés par Apple. Ces seuils demandent d’atteindre un volume précis d’utilisateurs pour remonter des données exploitables, ce qui rend l’analyse granulaire souvent impossible.
Si SKAN est adapté pour des campagnes centrées sur les installations, il atteint vite ses limites pour des objectifs avancés comme les abonnements par exemples. Côté retargeting, il reste peu pertinent, rendant son utilisation compliquée pour aller au-delà de l’acquisition.
Modèle Probabiliste
Le modèle probabiliste offre une lisibilité complète, couvrant à la fois les volumes d’installations et les données post-install. Contrairement à SKAN, il permet d’avoir une visibilité granulaire sur les actions in-app, telles que les achats, apportant ainsi des insights clés pour des campagnes à objectifs avancés.
Cette profondeur dans l’analyse des données post-install est essentielle pour optimiser les performances, là où SKAN atteint rapidement ses limites. Cependant, une configuration précise des fenêtres d’attribution est indispensable pour garantir des données fiables et éviter les biais.
Round 4 : Complexité de mise en œuvre
SKAN
La mise en place de SKAN peut être un vrai défi. Comprendre les concepts techniques tels que les postbacks, les valeurs coarse et grained, ou encore la gestion des fenêtres d’attribution, demande une expertise spécifique. Ces exigences peuvent compliquer son adoption pour des annonceurs moins expérimentés.
Modèle Probabiliste
À l’inverse, le modèle probabiliste est souvent perçu comme plus simple, grâce à la gestion facilitée via les MMP. Cependant, cette simplicité peut être trompeuse : un mauvais paramétrage peut avoir des conséquences négatives sur les résultats. Il nécessite une gestion rigoureuse des fenêtres d’attribution pour éviter les biais, car une mauvaise configuration peut rapidement mener à une sur ou sous-attribution.
Pour garantir une vue cohérente et exploitable, il est souvent nécessaire d’ajuster les données probabilistes afin de les aligner avec les volumes d’installations de SKAN, reconnus pour leur fiabilité.
Conclusion : Deux méthodes, deux approches
Impossible de départager ces deux approches dans cette battle. SKAN reste une solution fiable pour les volumes d’installations, avec un cadre clair et universel qui assure une stabilité durable face aux évolutions des politiques d’Apple. Toutefois, il atteint vite ses limites dès qu’il s’agit de suivre des performances in-app où sa granularité reste insuffisante.
Le modèle probabiliste, quant à lui, se distingue par une précision renforcée sur les performances in-app et les objectifs avancés, offrant une vue détaillée et exploitable pour des stratégies complexes. Mais côté conformité, c’est une solution instable, dont la pérennité dépend des évolutions du marché. Elle peut également peut fausser les résultats si elle est mal calibrée, donc c’est un modèle à bien maitriser
Le bon choix d’attribution pourrait ne pas être une question de « ou, » mais de « et. ». En combinant les forces des deux modèles, les annonceurs peuvent construire des stratégies solides : s’appuyer sur la stabilité et la fiabilité de SKAN pour les installations, tout en tirant parti de la granularité et de l’agilité du modèle probabiliste pour des campagnes plus ambitieuses.
ACTUALITÉS
Article en relation

Pourquoi l’Ad Fatigue s’accélère en 2026 (et comment…
L’Ad Fatigue désigne la baisse progressive de performance d’une publicité lorsqu’elle est vue trop souvent par la même audience. Résultat : le message...
Publié le 10 mai 2026
Du premier achat à la valeur long terme…
Depuis plusieurs années, les stratégies d’acquisition mobile ont fortement évolué. Mais un réflexe reste encore très présent : évaluer la performance d’une campagne...
Publié le 30 avril 2026
Coupe du Monde 2026 : Comment profiter de ce…
La Coupe du Monde 2026 est un temps fort marketing unique, car elle repose sur des pics d’attention liés aux matchs, et non...
Publié le 27 avril 2026

